Where Non-PhD Bioinformatics Hires Come From
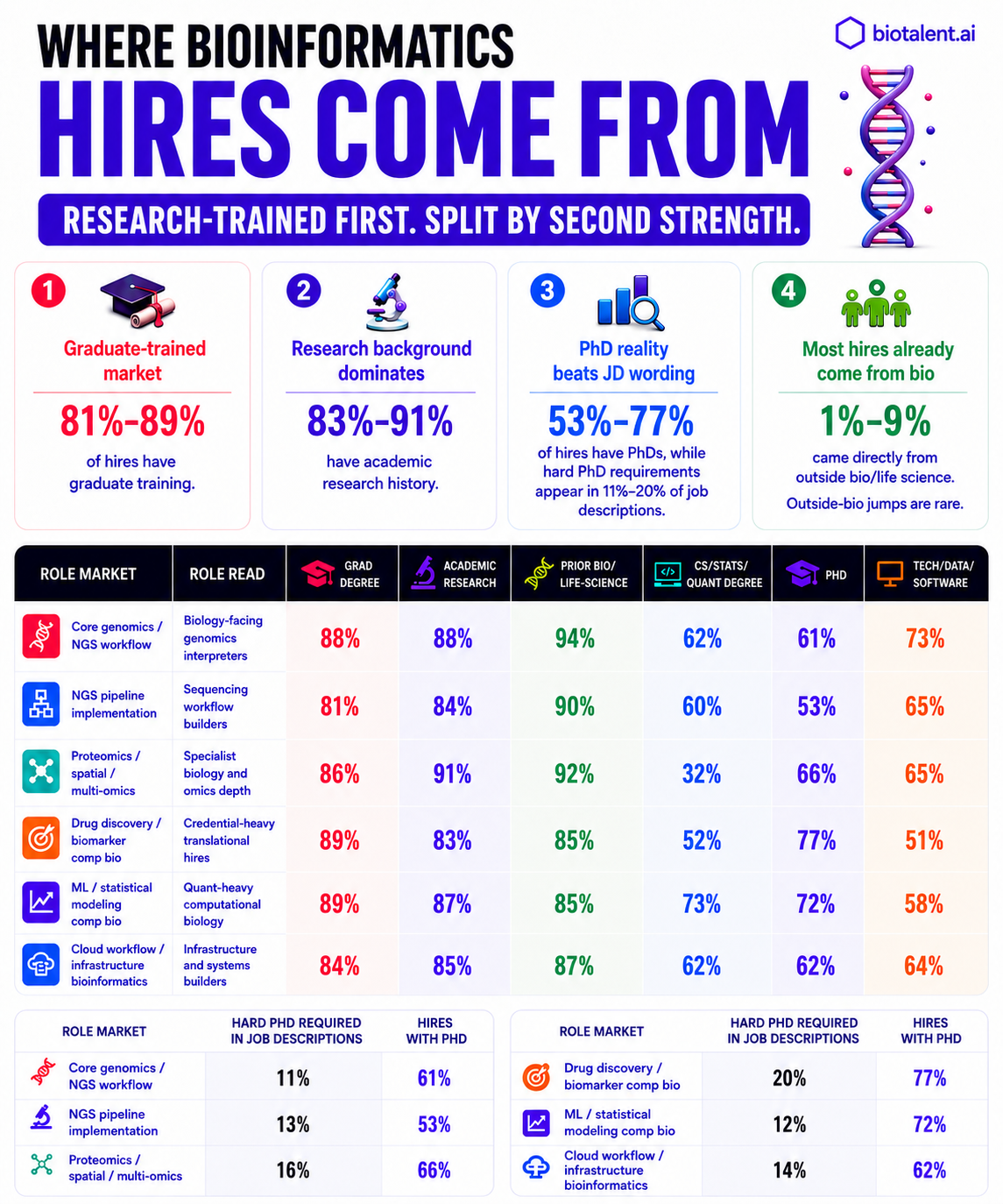
Bioinformatics is not an easy market to break into without advanced training. Across the six bioinformatics role markets biotalent.ai mapped, the people already doing these jobs are usually graduate-trained, research-heavy, and anchored in biology.
That does not mean the bachelor’s or master’s route is closed. It tends to work differently: successful non-PhD candidates usually bring another strength the employer already knows how to trust.
The baseline is credential-heavy
Across the six bioinformatics role markets biotalent.ai mapped, the numbers are hard to ignore.
If a hiring team opens a bioinformatics search, it should assume the market is full of candidates with advanced degrees, research backgrounds, and direct life-science context.
But that does not mean the bachelor’s or master’s route is closed. It just tends to work differently.
The successful non-PhD candidates usually bring another strength the employer already knows how to trust: software systems, data engineering, analytics engineering, workflow ownership, quant training, or scientific operations.
In other words, they are not getting hired because they vaguely match “bioinformatics.” They are getting hired because they have solved a real operating problem before.
A sequencing pipeline needed to become more reliable. A data workflow needed ownership. A clinical genomics team needed stronger software discipline. A research group needed someone who could sit between scientists, data, and execution. That is usually where the door opens.
| Pattern | Share |
|---|---|
| PhD share | 53% to 77% |
| Graduate training | 81% to 89% |
| Academic research history | 83% to 91% |
What the non-PhD path tends to look like
In the refined bachelor’s/master’s success pool from top employers, a few patterns kept showing up.
The point is not that these candidates skipped the hard parts. It is that many of them earned credibility in another lane first.
They proved they could ship software, manage messy data, own workflows, support scientific operations, or bring quantitative depth to a real team. Then they moved closer to bioinformatics as their work became more valuable inside a scientific setting.
That should change how employers source.
A bachelor’s or master’s candidate with a generic bioinformatics keyword match is not enough. A candidate who has already owned data systems, testing, workflow reliability, software infrastructure, or quantitative analysis inside a scientific company is a very different profile.
| Pattern | Share |
|---|---|
| Came from a non-bioinformatics title right before the current role | 86% |
| Had prior tech, data, or software experience | 77% |
| Had a CS, statistics, or quantitative education background | 71% |
| Stayed in the current role or company long enough to build trust | 72% |
| Showed some form of internal progression | 41% |
Illumina: from software systems to analytics engineering
One Illumina engineer came through the systems side of the business.
This person started in engineering and automation work, spent years around software systems and product transfer, then moved into technical program and software management before landing in analytics engineering leadership.
The academic background was bioengineering, which gave the biology context. But the career story is really about operational trust: automation, software, internal systems, handoffs, and analytics work inside genomics.
That kind of path makes sense for NGS pipeline work. The employer is not just seeing “bioinformatics.” They are seeing someone who has lived close to the machinery that makes genomics workflows run.
Guardant Health: from test automation to bioinformatics software
One Guardant Health bioinformatics software engineer started in software testing and automation before moving into bioinformatics software.
That path can look surprising from a distance, but it makes a lot of sense in clinical genomics.
These teams need pipelines that are reproducible, testable, and reliable. A person who has spent years making software behave under real production pressure can be valuable, even without the classic PhD computational biology background.
In this case, the computer science foundation matters. So does the testing background. Clinical sequencing workflows are unforgiving, and software quality is not a side issue.
Exact Sciences: from data work to bioinformatics engineering
One Exact Sciences bioinformatics engineer came through analytics and data engineering.
The early work was not bioinformatics in title. It was data analysis, reporting, governance, metrics, and data systems. Over time, that turned into data engineering work, and then into bioinformatics engineering.
That is a plausible path because a lot of bioinformatics work is less glamorous than people imagine.
The job often depends on whether data is clean, traceable, well-modeled, and usable across teams. Someone who has already handled those problems in a healthcare or diagnostics environment may be closer to the work than their title suggests.
Broad Institute: from research operations to data science
One Broad Institute data scientist came from the biology and clinical research side.
This person had molecular biology training, spent time around research coordination and patient-linked study work, then moved into data science inside a major research environment.
That is a different route from the software-first people in this group.
Here, the value comes from understanding the scientific setting: the studies, the handoffs, the data context, the patient or sample story, and the way research teams actually operate. The technical layer came later, but it was built on top of real biology fluency.
For teams doing computational work close to research operations, that combination can be useful.
Illumina: from CS training to senior software work in genomics
Another Illumina engineer followed the cleaner software-first path.
This person had a computer science background with bioinformatics exposure, then built a software engineering career inside a genomics company.
There is no complicated conversion story here. It is a strong CS profile that grew inside the right environment.
For pipeline, workflow, and infrastructure roles, that is often exactly what the team needs: someone who can build production-grade software while understanding enough of the scientific context not to get lost.
What employers should do with this
The bachelor’s/master’s path into bioinformatics is usually not a generic “bioinformatics” path. It is a second-strength path.
For pipeline and workflow roles, look hard at people with software reliability, testing, data engineering, and workflow ownership.
For infrastructure roles, look for production systems, cloud or HPC exposure, orchestration, and enough genomics context to work with scientific teams.
For biology-facing roles, look for people who have been close to research, disease areas, assays, modalities, or clinical study operations.
For modeling roles, look for statistics, ML, quantitative training, and enough biology judgment to know when an output makes scientific sense.
The title may say bioinformatics, but the actual job usually rewards something more specific.
Sometimes it rewards software discipline. Sometimes it rewards data plumbing. Sometimes it rewards scientific judgment. Sometimes it rewards the person who can keep a workflow alive when the handoffs are messy and the stakes are high.
That should shape the search before the first outreach message goes out.
It affects where to source, which resumes deserve a closer look, and how to build the interview loop. The goal is not to find the candidate who sounds most bioinformatics-adjacent.
The goal is to find the person whose previous work matches the pain the team is actually hiring against.
biotalent.ai helps biotech employers map role requirements, candidate backgrounds, compensation bands, and sourcing lanes before the search starts.
Your first talent search and first three introductions are free.